Particles
chombo-discharge supports computational particles using native Chombo particle data.
The source code for the particle functionality resides in $DISCHARGE_HOME/Source/Particle.
Particle support contains the following basic features:
Particle-mesh operations, i.e., deposition and interpolation of particle variables to/from the mesh.
Particle distribution and remapping with MPI.
Rudimentary particle output to H5Part files.
Particle support is generally speaking templated, so that users can define new particle types that contain a desired set of variables. Typically, these will are derived from GenericParticle, which is discussed below.
GenericParticle
GenericParticle is a default particle usable by the Chombo particle library.
The particle type is essentially a template
/**
@brief A generic particle class, holding the position and a specified number of real and vector values.
@details For the sake of simplicity, I have added separate linearization functions H5size, H5linearOut, H5linearIn that only linearizes
the Real components of the particle. This is done for convenience only, so I don't have to rewrite all of Chombo's particle HDF5 checkpointing
routines. Instead, we simply run a bootleg version of those codes that call the H5 linearization versions instead of the regular linearization
functions. Users can use this functionality for trimming other types of unnecessary properties that don't need to go into the HDF5 files.
*/
template <size_t M, size_t N>
class GenericParticle
where M and N are the number of Real and RealVect variables for the particle.
The GenericParticle always stores the position of the particle, which is available through GenericParticle<M,N>::position.
To fetch the Real and RealVect variables, GenericParticle has member functions
/**
@brief Get one of the scalars.
@details Template parameter is the position in the m_scalars array. This is templated so that compilers may throw
compile-time errors if trying to fetch elements out of range.
@return m_scalars[K]
*/
template <size_t K>
inline Real&
real();
/**
@brief Get one of the RealVects.
@details Template parameter is the position in the m_vectors array. This is templated so that compilers may throw
compile-time errors if trying to fetch elements out of range.
@return m_vectors[K]
*/
template <size_t K>
inline RealVect&
vect();
If using GenericParticle directly, the correct C++ way of fetching one of these variables is
GenericParticle<2,2> p;
Real& s = p.template real<0>();
Note that one must include the template keyword.
GenericParticle can also store the local (per MPI rank) particle ID and the MPI rank ID on the particle.
These are available through member functions particleID() and rankID.
Tip
The GenericParticle C++ API is found at https://chombo-discharge.github.io/chombo-discharge/doxygen/html/classGenericParticle.html.
Linearization functions
GenericParticle has linearization functions communicating particles with MPI, as well as for supplying output to HDF5 checkpoint files.
By default, GenericParticle will communicate all particle properties (including rank ID and particle ID), and include all Real member values in the HDF5 checkpoint files.
For particles that do not need to checkpoint all particle properties when writing HDF5 checkpoint files, it may be beneficial to reduce the file size by only exporting the necessary particle properties (e.g., the position and particle weight).
Custom particles
To create a simple custom particle class with more sane signatures, one can inherit from GenericParticle and specify new function signatures that return the appropriate fields.
An example of this is given in the code-block below, where we define KineticParticle to be a particle that contains the th5ree additional fields on top of GenericParticle (weight, velocity, and acceleration).
class KineticParticle : public GenericParticle<1,2>
{
public:
inline
Real& weight() {
return this->real<0>();
}
inline
RealVect& velocity() {
return this->vect<0>();
}
inline
RealVect& acceleration() {
return this->vect<1>();
}
};
There are many particles in chombo-discharge, see the GenericParticle C++ API for more information.
ParticleContainer
The ParticleContainer<P> is a template class that
Stores computational particles of type
Pover an AMR hierarchy.Provides infrastructure for remapping particles.
Provides functionality for getting a list of particles within a specified grid patch.
Provides functionality that is required during regrids.
Other types of functionality, like grouping particles into grid cells, set and get functions for assigning particle variables, etcl.
ParticleContainer<P> uses the Chombo structure ParticleData<P> under the hood, and therefore has template constraints on P.
The simplest way to use ParticleContainer for a new type of particle is to let P inherit from GenericParticle, which will fulfill all template constraints.
Data structures
List<P> and ListBox<P>
At the lowest level the particles are always stored in a linked list List<P>.
The class can be simply be through of as a regular list of P with non-random access.
The ListBox<P> consists of a List<P> and a Box.
The latter specifies the grid patch that the particles are assigned to.
To get the list of particles from a ListBox<P>:
ListBox<P> myListBox;
List<P>& myList = myListBox.listItems();
ListIterator<P>
In order to iterate over particles, use an iterator ListIterator<P> (which is not random access):
List<P> myParticles;
for (ListIterator<P> lit(myParticles); lit.ok(); ++lit){
P& p = lit();
// ... do something with this particle
}
ParticleData<P>
On each grid level, ParticleContainer<P> stores the particles in a Chombo class ParticleData.
template <class P>
ParticleData<P>
where P is the particle type.
ParticleData<P> can be thought of as a LevelData<ListBox<P>>, although it actually inherits from LayoutData<ListBox<P>>.
Each grid patch contains a ListBox<P> of particles.
AMRParticles<P>
AMRParticles<P> is our AMR version of ParticleData<P>.
It is a simply a typedef of a vector of pointers to ParticleData<P> on each level:
template <class P>
using AMRParticles = Vector<RefCountedPtr<ParticleData<P>>>;
Again, the Vector indicates the AMR level and the ParticleData<P> is a distributed data holder that holds the particles on each AMR level.
AMRParticles<P> always lives within ParticleContainer<P>, and is the class member of ParticleContainer<P> that actually holds the particles.
Basic usage
Here, we give some examples of basic usage of ParticleContainer.
For the full API, see the ParticleContainer C++ API https://chombo-discharge.github.io/chombo-discharge/doxygen/html/classParticleContainer.html.
Getting the particles
To get the particles from a ParticleContainer<P> one can call AMRParticles<P>& ParticleContainer<P>::getParticles() which will provide the particles:
ParticleContainer<P> myParticleContainer;
AMRParticles<P>& myParticles = myParticleContainer.getParticles();
Alternatively, one can fetch directly from a specified grid level as follows:
int lvl;
ParticleContainer<P> myParticleContainer;
ParticleData<P>& levelParticles = myParticleContainer[lvl];
Iterating over particles
To do something basic with the particle in a ParticleContainer<P>, one will typically iterate over the particles in all grid levels and patches.
The code bit below shows a typical example of how the particles can be moved, and then remapped onto the correct grid patches and ranks if they fall off their original one.
ParticleContainer<P> myParticleContainer;
// Iterate over grid levels
for (int lvl = 0; lvl <= m_amr->getFinestLevel(); lvl++){
// Get the grid on this level.
const DisjointBoxLayout& dbl = m_amr->getGrids(myParticleContainer.getRealm())[lvl];
// Get the distributed particles on this level
ParticleData<P>& levelParticles = myParticleContainer[lvl]
// Iterate over grid patches on this level
for (DataIterator dit(dbl); dit.ok(); ++dit){
// Get the particles in the current patch.
List<P>& patchParticles = levelParticles[dit()].listItems();
// Iterate over the particles in the current patch.
for (ListIterator<P> lit(patchParticles); lit.ok(); ++lit){
P& p = lit();
// Move the particle
p.position() = ...
}
}
}
// Remap particles onto new patches and ranks (they may have moved off their original ones)
myParticleContainer.remap();
Sorting particles
Sorting by cell
The particles can also be sorted by cell by calling void ParticleContainer<P>::sortParticleByCell(), like so:
ParticleContainer<P> myParticleContainer;
myParticleContainer.sortParticlesByCell();
Internally in ParticleContainer<P>, this will place the particles in another container which can be iterated over on a per-cell basis.
This is different from List<P> and ListBox<P> above, which contained particles stored on a per-patch basis with no internal ordering of the particles.
The per-cell particle container is a Vector<RefCountedPtr<LayoutData<BinFab<P>>>> type where again the Vector holds the particles on each AMR level and the LayoutData<BinFab> holds one BinFab on each grid patch.
The BinFab is also a template, and it holds a List<P> in each grid cell.
Thus, this data structure stores the particles per cell rather than per patch.
Due to the horrific template depth, this container is typedef’ed as AMRCellParticles<P>.
To get cell-sorted particles one can call
AMRCellParticles<P>& cellSortedParticles = myParticleContainer.getCellParticles();
Iteration over cell-sorted particles is mostly the same as for patch-sorted particles, except that we also need to explicitly iterate over the grid cells in each grid patch:
const int comp = 0;
// Iterate over all AMR levels
for (int lvl = 0; lvl <= m_amr->getFinestLevel(); lvl++){
// Get the grids on this level
const DisjointBoxLayout& dbl = m_amr->getGrids(myParticleContainer.getRealm())[lvl];
// Iterate over grid patches on this level
for (DataIterator dit(dbl); dit.ok(); ++dit){
// Get the Cartesian box for the current grid aptch
const Box cellBox = dbl[dit()];
// Get the particles in the current grid patch.
BinFab<P>& cellSortedBoxParticles = (*cellSortedParticles[lvl])[dit()];
// Iterate over all cells in the current box
for (BoxIterator bit(cellBox); bit.ok(); ++bit){
const IntVect iv = bit();
// Get the particles in the current grid cell.
List<P>& cellParticles = cellSortedBoxParticles(iv, comp);
// Do something with cellParticles
for (ListIterator<P> lit(cellParticles); lit.ok(); ++lit){
P& p = lit();
}
}
}
}
Sorting by patch
If the particles need to return to patch-sorted particles:
ParticleContainer<P> myParticleContainer;
myParticleContainer.sortParticlesByPatch();
Important
If particles are sorted by cell, calling ParticleContainer<P> member functions that fetch particles by patch will issue an error.
This is done by design since the patch-sorted particles have been moved to a different container.
Note that remapping particles also requires that the particles are patch-sorted.
Calling remap() with cell-sorted particles will issue a run-time error.
Allocating particles
AmrMesh has a very simple function for allocating a ParticleContainer<P>:
/**
@brief Template class for generic allocation of particle containers.
@param[out] a_container Particle container to be allocated
@param[out] a_realm Realm on which the particles will be allocated.
*/
template <typename T>
void
allocate(ParticleContainer<T>& a_container, const std::string& a_realm) const;
which will allocate a ParticleContainer on the realm a_realm.
Particle mapping
Particles that move off their original grid patch must be remapped in order to ensure that they are assigned to the correct grid.
The remapping function for ParticleContainer<P> is
void
addParticles(const ParticleContainer<P>& a_otherContainer);
/**
@brief Add particles from other container to this one. This destroys the particles in the other container.
This is simply used as follows:
ParticleContainer<P> myParticles;
myParticles.remap();
During remapping, the following steps are performed for each MPI rank:
Collect all particles from this rank onto thread-local particles (if using OpenMP).
Iterate through those particles and locate their position in the AMR hierarchy (level, grid index, and owning MPI rank).
The particles that will move off each MPI rank are put in separate data containers.
Assign local particles first, i.e., particles that moved off a grid patch into another grid patch owned by the same rank.
Scatter the particles with MPI.
Assign the scattered particles to each MPI rank.
Regridding
As with mesh data, ParticleContainer<P> requires storing the old-grid data before assigning data on the new grids.
This is relatively simple to achieve, and is done as follows:
Before creating the new grids, each MPI rank collects all particles on a single
List<P>by calling/** @brief Cache particles before calling regrid. @param[in] a_lmin Coarsest grid level which will not change. */ void preRegrid(int a_lmin);
This will pull the particles off their current grids and collect them in a single list (on a per-rank basis).
When
ParticleContainer<P>regrids, each rank adds hisList<P>back into the internal particle containers.This is done by calling the
ParticleContainer<P>regrid function:/** @brief Regrid function. a_base is the coarsest grid level which did not change @param[in] a_grids AMR grids @param[in] a_domains AMR domains @param[in] a_dx Grid resolutions @param[in] a_refRat Refinement ratios @param[in] a_validMask Valid cells @param[in] a_levelTiles Tiled AMR grids @param[in] a_base Coarsest grid level that did not change. @param[in] a_newFinestLevel New finest grid level */ void regrid(const Vector<DisjointBoxLayout>& a_grids, const Vector<ProblemDomain>& a_domains, const Vector<Real>& a_dx, const Vector<int>& a_refRat, const Vector<ValidMask>& a_validMask, const Vector<RefCountedPtr<LevelTiles>>& a_levelTiles, int a_base, int a_newFinestLevel);
Warning
One must call preRegrid before the regrid.
Failure to do so will lead to loss of all particles.
Masked particles
ParticleContainer<P> also supports the concept of masked particles, where one can fetch a subset of particles that live only in specified grid cells.
Typically, this “specified region” is the refinement boundary, but the functionality is generic and might prove useful also in other cases.
This functionality is unlikely to be used directly by users of chombo-discharge, but it is nonetheless fruitful to understand the concept in order to more easily fathom how deposition across refinement boundaries proceed.
When masked particles are used, the user can provide a boolean mask over the AMR hierarchy and obtain the subset of particles that live in regions where the mask evaluates to true.
This functionality is for example used for some of the particle deposition methods in chombo-discharge where we deposit particles that live near the refinement boundary with special deposition functions.
To fill the masked particles, ParticleContainer<P> has members functions for copying the particles into internal data containers which the user can later fetch.
The function signatures for this is
/**
@brief Copy particles to mask particle data holder.
@param[in] a_mask Mask
@note If the mask is nullptr on any of the levels, those levels will be ignored.
*/
void
copyMaskParticles(const Vector<RefCountedPtr<LevelData<BaseFab<bool>>>>& a_mask) const;
The argument a_mask holds a bool at each cell in the AMR hierarchy.
Particles that live in cells where a_mask is true will be copied to an internal data holder in ParticleContainer<P> which can be retrieved through a call
/**
@brief Get the mask particles.
@return m_maskParticles
*/
AMRParticles<P>&
getMaskParticles();
In the above functions the mask particles are copied, and the original particles are left untouched. After the user is done with the particles, they should be deleted through the function
/**
@brief Clear the "mask" particles.
*/
void
clearMaskParticles() const;
An example pseudocode for working with masked particles is given below:
AmrMask myMask;
ParticleContainer<P> myParticles;
// Copy mask particles
myParticles.copyMaskParticles(myMask);
// Do something with the mask particles
AMRParticles<P>& maskParticles = myParticleContainer.getMaskParticles();
// Release the mask particles
myParticles.clearMaskParticles();
Boundary interaction
ParticleContainer<P> is EB-agnostic and has no information about the embedded boundary and only partial information about the domain boundary.
This means the following:
Particles remap just as if the embedded boundary was not there.
Particles that completely fall off the domain are deleted when calling the remapping function.
Interaction with the EB is done via the implicit function or discrete information, as well as modifications in the interpolation and deposition steps.
Signed distance function
When signed distance functions are used, one can always query how far a particle is from a boundary:
List<P>& particles;
BaseIF distanceFunction;
for (ListIterator<P> lit(particles); lit.ok(); ++lit){
const P& p = lit();
const RealVect& pos = p.position();
const Real distanceToBoundary = distanceFunction.value(pos);
}
If the particle is inside the EB then the signed distance function will be positive, and the particle can then be removed from the simulation. The distance function can also be used to detect collisions between particles and the EB. E.g, the intersection point can be computed and the particle can be deposited on the boundary, or bounced off it. See AmrMesh for details on how to obtain the distance function.
Domain edges
By default, the ParticleContainer remapping function will discard particles that fall outside of the domain.
The user can also check if this happen by checking if the particle position is outside the computational domain:
GenericParticle<0,0> p;
const RealVect pos = p.position();
const RealVect probLo = m_amr->getProbLo();
const RealVect probHi = m_amr->getProbHi();
bool outside = false;
for (int dir = 0; dir < SpaceDim; dir++) {
if(pos[dir] < probLo[dir] || pos[dir] > probHi[dir]) {
outside = true;
}
}
Particle intersection
It is occasionally useful to catch particles that hit an EB or crossed a domain side.
Assuming that the particle type P also has a member function that stores the starting position of the particle, one can compute the intersection point between the particle trajectory and the EB or domain sides.
Currently, AmrMesh supports two methods for computing this
Using a bisection algorithm with a user-specified step.
Using a ray-casting algorithm.
These algorithms differ in the sense that the bisection approach will check for a particle crossing between two positions \(\mathbf{x}_0\) and \(\mathbf{x}_1\) using a pre-defined tolerance. The ray-casting algorithm will check if the particle can move from \(\mathbf{x}_0\) towards \(\mathbf{x}_1\) by using a variable step along the particle trajectory. This step is selected from the signed distance from the particle position to the EB such that it uses a large step if the particle is far away from the EB. Conversely, if the particle is close to the EB a small step will be used.
The algorithm that intersect the particles are a part of AmrMesh, and are called as follows:
/**
@brief Particle intersection algorithm based on ray-casting.
@details This routine will iterate through all the particles and check if they intersect the geometry. The template
parameter indicates the particle type -- it MUST have const RealVec& position() const and const RealVect& oldPosition() const
functions that determine the start and stop position of the particle trajectory. This routine uses a ray-casting method
to check for intersections with the EB (the domain side is much easier). If the particles are closer to the EB than
a_tolerance, they are absorbed and placed on the EB. Their position are updated and they are placed in the
a_ebParticles argument. This routine uses a ray-casting method where it computes the distance from the EB
(assuming that the implicit function is a signed distance function). Particles are then moved that
distance along their trajectory and we then update the new distance to the EB. This is done recursively until the particles
have either moved the entire length or been absorbed by the EB or domain side.
@param[in,out] a_activeParticles Particles to be intersected with geometry
@param[out] a_ebParticles Particles that intersected with the EB
@param[out] a_domainParticles Particles that intersected with the domain faces
@param[in] a_phase Phase where the input particles live
@param[in] a_deleteParticles If true, particles will be removed from a_activeParticles if they intersect the geometry.
@param[in] a_nonDeletionModifier Optional input argument for letting the user manipulate particles that were intersected but not deleted
@param[in] a_tolerance Tolerance
*/
template <class P>
void
intersectParticlesRaycastIF(
ParticleContainer<P>& a_activeParticles,
ParticleContainer<P>& a_ebParticles,
ParticleContainer<P>& a_domainParticles,
const phase::which_phase a_phase,
const Real a_tolerance,
const bool a_deleteParticles,
const std::function<void(P&)>& a_nonDeletionModifier = [](P&) -> void {
return;
}) const noexcept;
/**
@brief Particle intersection algorithm based on bisection.
@details This routine will iterate through all the particles and check if they intersect the geometry. The template
parameter indicates the particle type -- it MUST have const RealVec& position() const and const RealVect& oldPosition() const
functions that determine the start and stop position of the particle trajectory. This routine uses a bisection method
to check for intersections with the EB (the domain side is much easier). Their position are updated and they are placed
in the a_ebParticles argument.
@param[in,out] a_activeParticles Particles to be intersected with geometry
@param[out] a_ebParticles Particles that intersected with the EB
@param[out] a_domainParticles Particles that intersected with the domain faces
@param[in] a_phase Phase where the input particles live
@param[in] a_bisectionStep Length of the bisection step
@param[in] a_deleteParticles If true, particles will be removed from a_activeParticles if they intersect the geometry.
@param[in] a_nonDeletionModifier Optional input argument for letting the user manipulate particles that were intersected but not deleted
*/
template <class P>
void
intersectParticlesBisectIF(
ParticleContainer<P>& a_activeParticles,
ParticleContainer<P>& a_ebParticles,
ParticleContainer<P>& a_domainParticles,
const phase::which_phase a_phase,
const Real a_bisectionStep,
const bool a_deleteParticles,
const std::function<void(P&)>& a_nonDeletionModifier = [](P&) -> void {
return;
}) const noexcept;
The above two functions take as input/output arguments the particles to be iterated through (a_activeParticles).
When calling the intersection functions, the intersected particles are put into EB-intersected particels (a_ebParticles) and domain-intersected particles (a_domainParticles).
The user can choose whether or not to remove intersected particles from a_activeParticles by adjusting a_deleteParticles.
The final argument lets the user supply a lambda that modifies particles that were intersected.
Important
The intersection functions require that P has a member function oldPosition which supplies the starting position of the particle.
Both the bisection and ray-casting algorithm have weaknesses.
The bisection algorithm algorithm requires a user-supplied step in order to operate efficiently, while the ray-casting algorithm is very slow when the particle is close to the EB and moves tangentially along it.
Future versions of chombo-discharge will likely include more sophisticated algorithms.
Tip
AmrMesh also stores the implicit function on the mesh, which could also be used to resolved particle collisions with the EB/domain.
Particle-mesh
Particle-mesh operations are required when particles interact with the mesh and vice-versa. There are two main operations involved:
Deposition, where particle properties are transferred to the mesh.
Interpolation, where mesh properties are transferred to the particles.
Particle deposition
To deposit particles on the mesh, the user can call the templated function AmrMesh::depositParticles which have a signatures
/**
@brief Deposit scalar particle quantities on the mesh.
@details P is the particle type, Ret is the returned value of the particle member function, and must be a Real or a
RealVect. MemFunc is a pointer to a member function of P. E.g., depositParticles<P, const RealVect&, &P::position>.
@param[out] a_meshData Mesh data. Must have exactly one component.
@param[in] a_realm Realm where data is registered.
@param[in] a_phase Phase where data is registered.
@param[in] a_particles Particle container. Must be in "usable state" for deposition.
@param[in] a_depositionType Specification of deposition kernel (e.g., CIC)
@param[in] a_coarseFineDeposition Specification of handling of coarse-fine boundaries.
@param[in] a_forceIrregNGP Force NGP deposition in irregular cells or not.
*/
template <class P, typename Ret, Ret (P::*MemberFunc)() const>
void
depositParticles(EBAMRCellData& a_meshData,
const std::string& a_realm,
const phase::which_phase& a_phase,
const ParticleContainer<P>& a_particles,
const DepositionType a_depositionType,
const CoarseFineDeposition a_coarseFineDeposition,
const bool a_forceIrregNGP = false);
/**
@brief Deposit scalar particle quantities on the mesh.
@details P is the particle type, Ret is the returned value of the particle member function, and must be a Real or a
const Real&. MemFunc is a pointer to a member function of P. E.g., depositParticles<P, const Real&, &P::weight>.
@param[out] a_meshData Mesh data. MUST have exactly one component.
@param[in] a_realm Realm where data is registered.
@param[in] a_phase Phase where data is registered.
@param[in] a_particles Particle container. Must be in "usable state" for deposition.
*/
template <class P, typename Ret, Ret (P::*MemberFunc)() const>
void
depositParticles(EBAMRIVData& a_meshData,
const std::string& a_realm,
const phase::which_phase& a_phase,
const ParticleContainer<P>& a_particles) const noexcept;
Here, the template parameter P is the particle type and the template parameter MemberFunc is a C++ pointer-to-member-function that returns Ret, which must either be a Real or a RealVect.
In addition, the function will accept const Real& or const RealVect&.
The pointer-to-member MemberFunc indicates the variable to be deposited on the mesh, and must have return type Ret.
This function pointer does not need to return a member in the particle class, but it must be marked const.
Next, the input arguments to depositParticles are the output mesh data holder (must have exactly one or SpaceDim components), the realm and phase where the particles live, and the particles themselves (a_particles).
Finally, the flag a_forceIrregNGP permits the user to enforce nearest grid-point deposition in cut-cells.
This option is motivated by the fact that some applications might require hard mass conservation, and the user can then ensure that mass is never deposited into covered grid cells.
The input argument a_depositionType indicates the deposition method, while a_coarseFineDeposition deposition modifications near refinement boundaries.
These are discussed below.
Base deposition
The base deposition scheme is specified by an enum DepositionType with valid values:
DepositionType::NGP(Nearest grid-point).DepositionType::CIC(Cloud-In-Cell).DepositionType::TSC(Triangle-Shaped Cloud).
chombo-discharge supports all of the above methods, which can be combined with various types of modifications near refinement boundaries.
Coarse-fine deposition
The input argument a_coarseFineDeposition determines how deposition near the coarse-fine deposition is handled.
Refinement boundaries introduce additional complications in the deposition scheme due to
Fine-grid particles whose deposition clouds hang over the refinement boundary and onto the coarse level.
Coarse-grid particles whose deposition clouds stick underneath the fine-level.
In addition, there can be complicated near physical boundaries, such as domain or embedded boundaries.
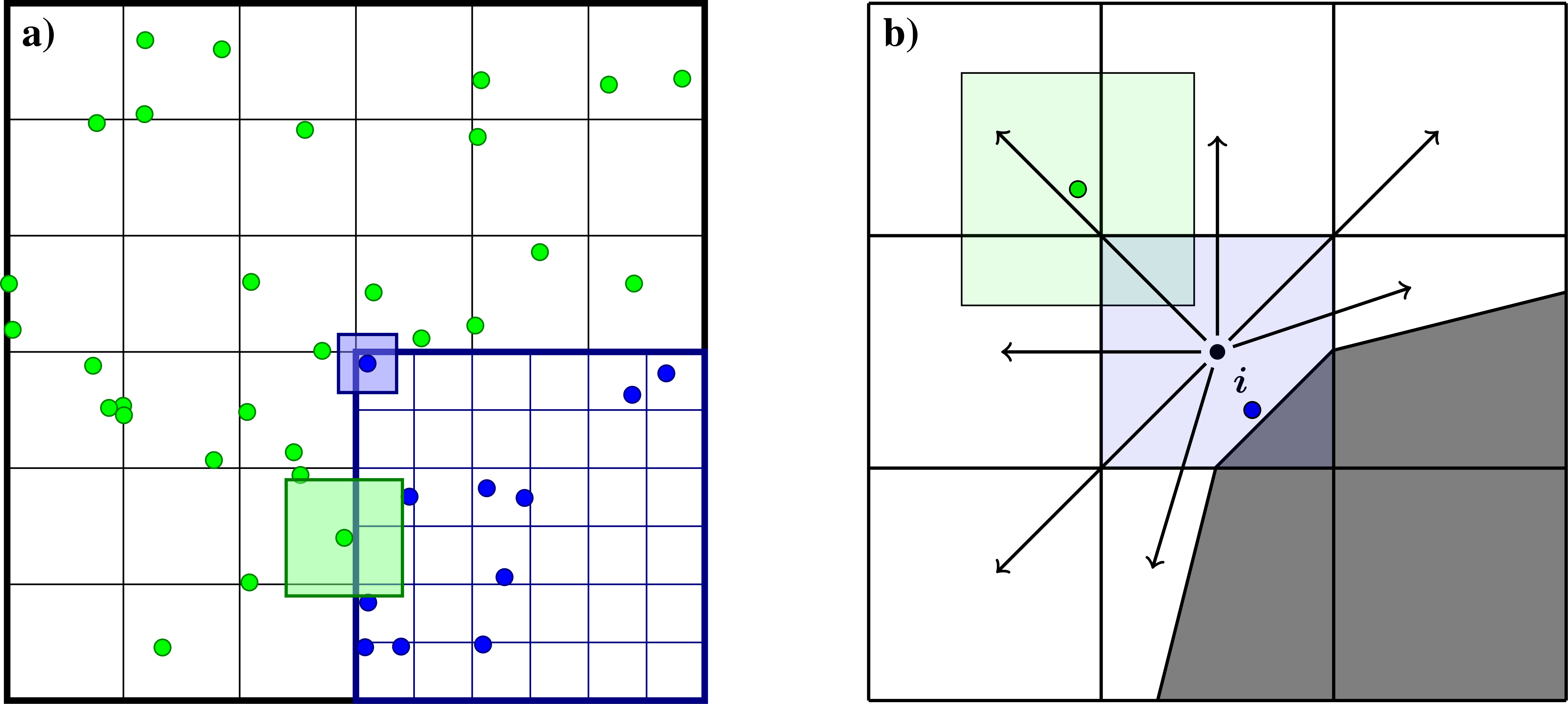
Fig. 11 Sketch of deposition schemes near refinement boundaries and cut-cells.
chombo-discharge support various ways of handling deposition across the refinement boundary.
In all of these methods, the mass on the fine grid particles whose deposition clouds hang over the refinement boundaries is simply added to the coarse grid.
The main modifications to the deposition scheme is performed for the coarse-grid particles that live around the refinement boundary (see Fig. 12).
For the coarse-grid particles the following processes then occur:
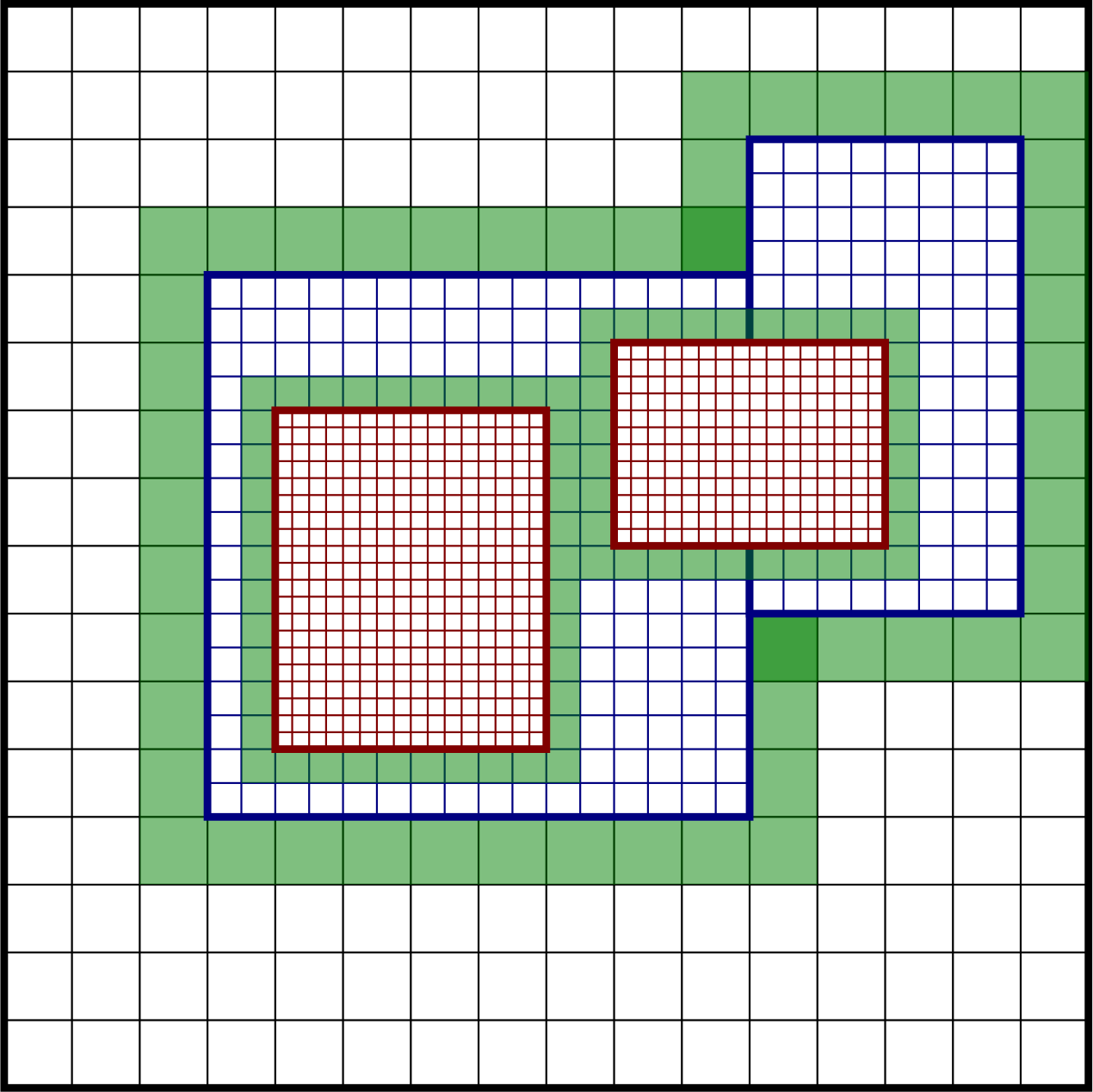
Fig. 12 Example regions containing coarse-grid particles that deposit with custom deposition rules.
The following coarse-fine deposition methods are currently supported:
CoarseFineDeposition::InterpThis method permits the coarse-grid particles to deposit into the region underneath the fine grid. The deposited mass that falls underneath the fine grid is then interpolated from the coarse grid to the fine grid. For example, see the indicated coarse-grid particle cloud in the left panel Fig. 11. While this particle has a width given by the coarse-grid cell size, it will deposit into the coarse grid cells underneath the fine grid. The mass that ends up in these cells is interpolated to the fine grid, which in this case will inject mass into two layers of fine-grid cells.CoarseFineDeposition::HaloThis method extracts the coarse-grid particles that live on the refinement boundary and deposit them with their original width on both the coarse and fine levels. This is done by first depositing the particles on the coarse level, and then transferring them to the fine level and redepositing them there with the original particle width. Taking the left panel in Fig. 11 as an example, the green particle will then deposit into the coarse-grid cell as well as the first layer of fine-grid cells.CoarseFineDeposition::HaloNGPSimilar toCoarseFineDeposition::Halodiscussed above, this method also extracts the coarse-grid particles on the coarse side of the refinement boundary. However, rather than using the original deposition scheme, these particles are deposited with an NGP scheme.CoarseFineDeposition::TransitionThis is a method that was developed in order to minimize spurious gradients in the density across the EB. This method operates by extracting the coarse-grid particles that live around the refinement zone (within some radius), and depositing them with the fine-grid particle width.
Important
Most coarse-fine particle deposition schemes exhibit some artifacts around the refinement boundary, especially when the particle width exceeds the grid cell size (e.g., for TSC).
The CoarseFineDeposition::Transition method is the one that we recommend, especially when used with CIC, as it eliminates spurious gradients across the refinement boundary.
Particle interpolation
To interpolate mesh data onto a particle property, the user can call the AmrMesh member functions
/**
@brief Interpolate mesh data onto a particle position.
@details P is the particle type, Ret is the returned value of the particle member function, and must be a Real& or a
RealVect&. MemFunc is a pointer to a member function of P. E.g., interpolate<P, Real&, &P::weight>.
@param[in,out] a_particles Particles to be interpolated.
@param[in] a_realm Realm where data is registered.
@param[in] a_phase Phase where data is registered.
@param[in] a_meshScalarField Scalar field on the mesh
@param[in] a_interpType Interpolation type.
@param[in] a_forceIrregNGP Force NGP interpolation in cut-cells.
*/
template <class P, class Ret, Ret (P::*MemberFunc)()>
void
interpolateParticles(ParticleContainer<P>& a_particles,
const std::string& a_realm,
const phase::which_phase& a_phase,
const EBAMRCellData& a_meshScalarField,
const DepositionType a_interpType,
const bool a_forceIrregNGP = false) const;
The function signature for particle interpolation is pretty much the same as for particle deposition, with the exception of the interpolated field.
The template parameter P still indicates the particle type, but the user can interpolate onto either a scalar particle variable or a vector variable.
For example, in order to interpolate the particle acceleration, the particle class (let’s call it MyParticleClass) will typically have a member function RealVect& acceleration(), and in this case one can interpolate the acceleration by
RefCountedPtr<AmrMesh> amr;
amr->interpolateParticles<MyParticleClass, RealVect&, &MyParticleClass::acceleration>(...)
Note
If the user interpolates onto a scalar variable, the mesh variable must have exactly one component.
Likewise, if interpolating a vector variable, the mesh variable must have SpaceDim components.
Example
Assume that we have some particle class KineticParticle defined as
class KineticParticle : public GenericParticle<1,2>
{
public:
inline
Real& weight() {
return this->real<0>();
}
inline
RealVect& velocity() {
return this->vect<0>();
}
inline
RealVect& acceleration() {
return this->vect<1>();
}
inline
RealVect momentum() const {
return this->weight() * this->velocity();
}
};
To deposit the weight, velocity, and momentum on the grid we would call
RefCountedPtr<AmrMesh> amr;
amr->depositParticles<KineticParticle, const Real&, &KineticParticle::mass >(...);
amr->depositParticles<KineticParticle, const RealVect&, &KineticParticle::velocity>(...);
amr->depositParticles<KineticParticle, const RealVect&, &KineticParticle::momentum>(...);
Likewise, to interpolate onto these fields we can call
RefCountedPtr<AmrMesh> amr;
amr->interpolateParticles<KineticParticle, Real&, &KineticParticle::mass >(...);
amr->interpolateParticles<KineticParticle, RealVect&, &KineticParticle::velocity>(...);
Particle visualization
Note
Particle visualization is currently a work in progress with limited functionality.
Simple particle visualization can be performed by writing H5Part compatible files which can be read by VisIt.
This is done through the function writeH5Part in the DischargeIO namespace, with the following signature:
/**
@brief Write a particle container to an H5Part file. Good for quick and dirty visualization of particles
@details Use case is pretty straightforward but the user might need to cast particle types. E.g. call
writeH5Part<M,N>(a_filename, (const ParticleContainer<GenericParticle<M,N>>&) a_particles, ...)
Template substitution is not straightforward for this one.
@param[in] a_filename File name
@param[in] a_particles Particles. Particle type must derive from GenericParticle<M, N>
@param[in] a_realVars Variable names for the M real variables
@param[in] a_vectVars Variable names for the N vector variables
@param[in] a_shift Particle position shift
@param[in] a_time Physical time
*/
template <size_t M, size_t N>
void
writeH5Part(std::string a_filename,
const ParticleContainer<GenericParticle<M, N>>& a_particles,
std::vector<std::string> a_realVars,
std::vector<std::string> a_vectVars,
RealVect a_shift,
Real a_time) noexcept;
This routine permits particles to be written (in parallel, when using MPI) into a file readable by VisIt.
The optional arguments a_realVars and a_vectVars permit the user to set the output variable names for the M scalar variables and the N vector variables.
The argument a_shift will simply shift the particle positions in the output HDF5 file.
Superparticles
Often, merging or splitting of particles is required.
In the most general case, users can simply interact directly with the particle list to modify the particles, which can be done either on a per-patch basis or within individual grid cells.
In each case one starts with a list List<P> that needs to be modified.
chombo-discharge has rather elementary support for handling superparticles.
Currently, we only support reinitialization of particles, or agglomeration of particles using kD-trees, as discussed below.
kD-trees
chombo-discharge has functionality for spatially partitioning particles using kD-trees, which can be used as a basis for particle merging and splitting.
kD-trees operate by partitioning a set of input primitives into spatially coherent subsets.
At each level in the tree recursion one chooses an axis for partitioning one subset into two new subsets, and the recursion continues until the partitioning is complete.
Fig. 13 shows an example where a set of initial particles are partitioned using such a tree.
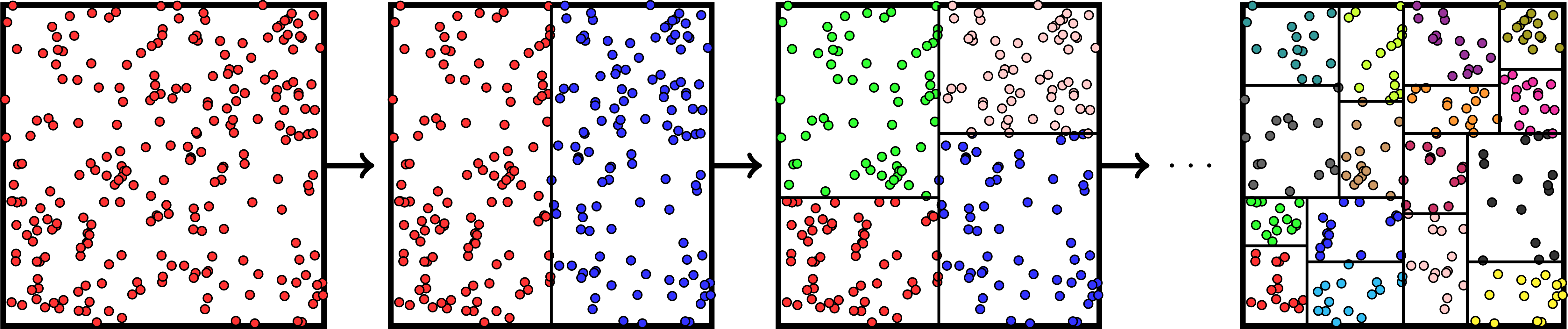
Fig. 13 Example of a kD-tree partitioning of particles in a single cell.
Tip
The source code for the kD-tree functionality is given in $DISCHARGE_HOME/Source/Particle/CD_SuperParticles.H.
The kD-tree partitioner requires a user-supplied criterion for particle partitioning.
Only the partitioner PartitionEqualWeight is currently supported, and this partitioner will divide the original subset into two new subsets such that the particle weights in the two halves differs by at most one physical particle.
This partitioner is implemented as
template <class P, Real& (P::*weight)(), const RealVect& (P::*position)() const>
typename KDNode<P>::Partitioner PartitionEqualWeight;
Here, P is the particle type, and this class must have function members Real& P::weight() and const RealVect& P::position() which return the particle weight and position.
Warning
PartitionEqualWeight will usually split particles to ensure that the weight in the two subsets are the same (thus creating new particles).
In this case any other members in the particle type are copied over into the new particles.
The particles in each leaf of the kD-tree can then be merged into new particles. Since the weight in the nodes of the tree differ by at most one, the resulting computational particles also have weights that differ by at most one.
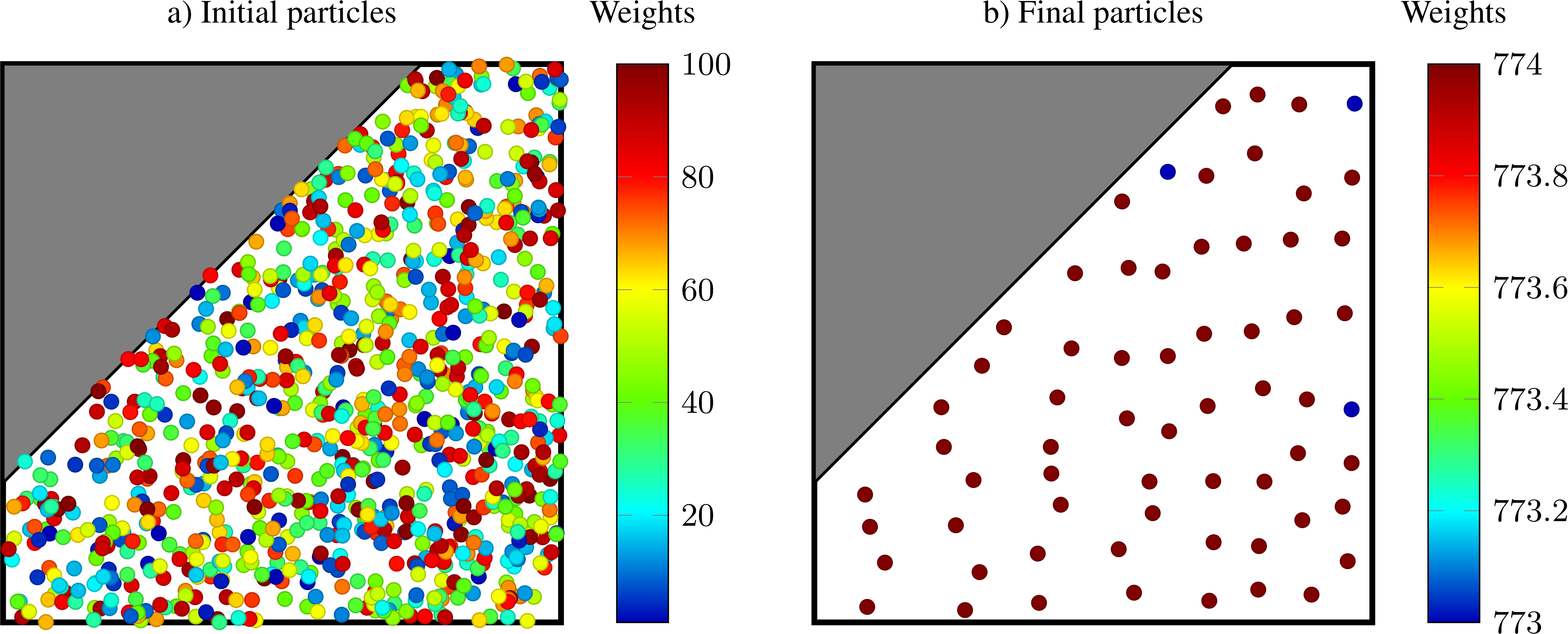
Fig. 14 kD-tree partitioning of particles into new particles whose weight differ by at most one. Left: Original particles with weights between 1 and 100. Right: Merged particles.